本文共 4147 字,大约阅读时间需要 13 分钟。
Google File System(GFS)的开源实现:HDFS
Google大数据“三驾马车”的第一驾是GFS(Google文件系统),而Hadoop的第一个产品是HDFS,可以说分布式文件存储是分布式计算的基础,也可见分布式文件存储的重要性。
HDFS是在一个大规模分布式服务器集群上,对数据分片后进行并行读写及冗余存储。
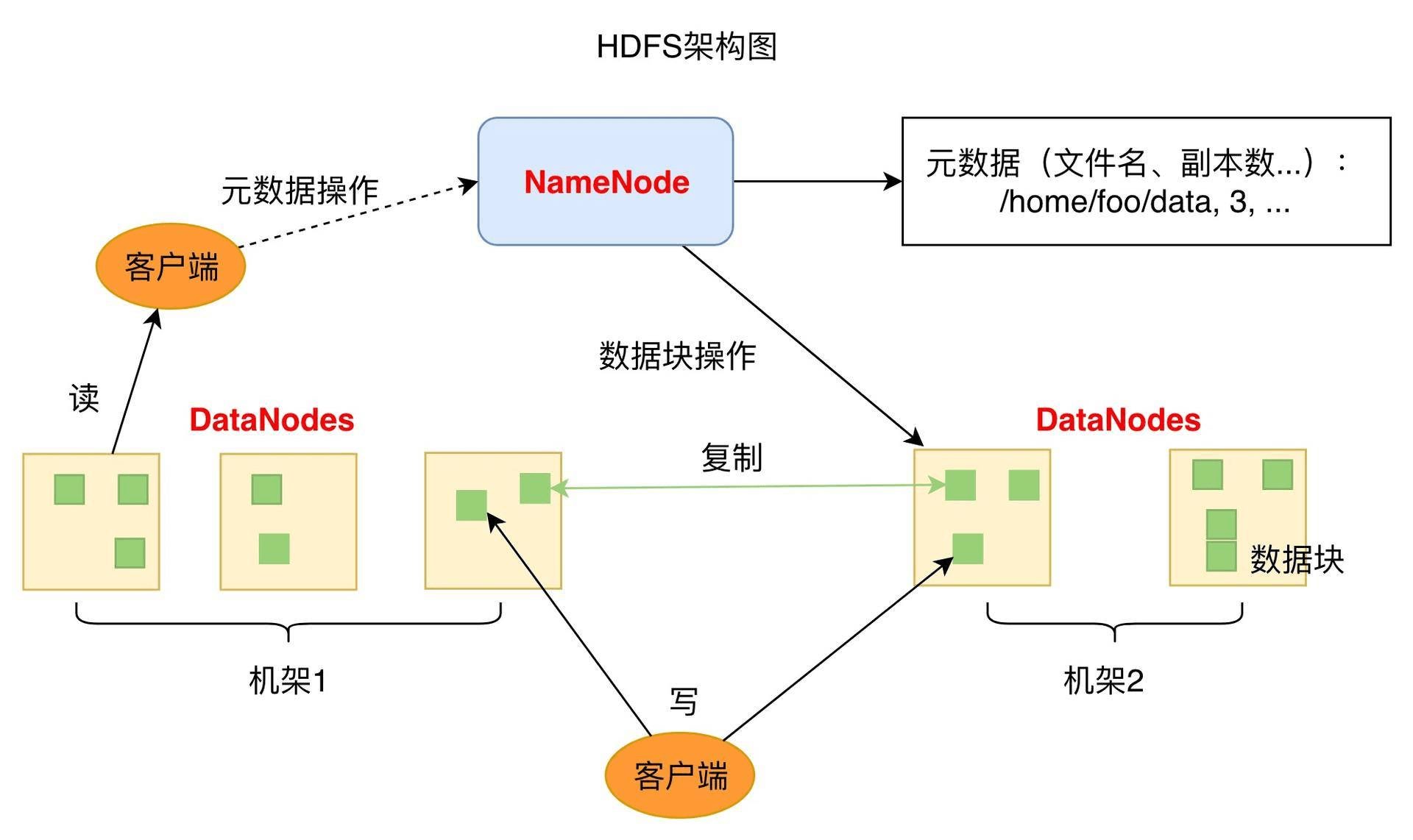 从图中你可以看到HDFS的关键组件有两个,一个是DataNode,一个是NameNode。
从图中你可以看到HDFS的关键组件有两个,一个是DataNode,一个是NameNode。 DataNode负责文件数据的存储和读写操作,HDFS将文件数据分割成若干数据块(Block),每个DataNode存储一部分数据块,这样文件就分布存储在整个HDFS服务器集群中。应用程序客户端(Client)可以并行对这些数据块进行访问,从而使得HDFS可以在服务器集群规模上实现数据并行访问,极大地提高了访问速度。
NameNode负责整个分布式文件系统的元数据(MetaData)管理,也就是文件路径名、数据块的ID以及存储位置等信息,相当于操作系统中文件分配表(FAT)的角色。HDFS为了保证数据的高可用,会将一个数据块复制为多份(缺省情况为3份),并将多份相同的数据块存储在不同的服务器上,甚至不同的机架上。这样当有磁盘损坏,或者某个DataNode服务器宕机,甚至某个交换机宕机,导致其存储的数据块不能访问的时候,客户端会查找其备份的数据块进行访问。
放大一下看数据块多份复制存储的实现。图中对于文件/users/sameerp/data/part-0,其复制备份数设置为2,存储的BlockID分别为1、3。Block1的两个备份存储在DataNode0和DataNode2两个服务器上,Block3的两个备份存储DataNode4和DataNode6两个服务器上,上述任何一台服务器宕机后,每个数据块都至少还有一个备份存在,不会影响对件/users/sameerp/data/part-0的访问。
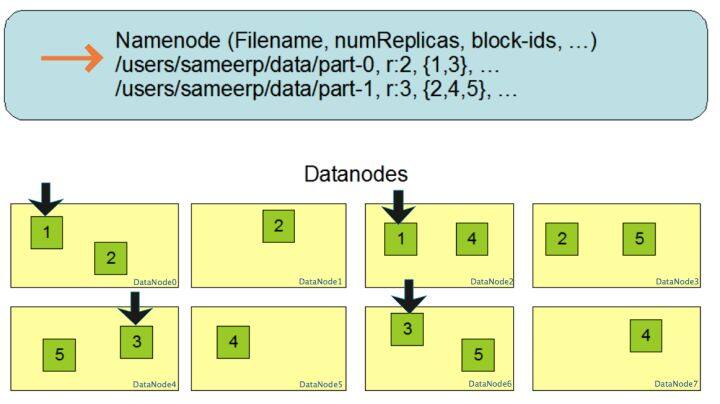
和RAID一样,数据分成若干数据块后存储到不同服务器上,可以实现数据大容量存储,并且不同分片的数据可以并行进行读/写操作,进而实现数据的高速访问。
MapReduce的开源实现:Hadoop MapReduce
在我看来,MapReduce既是一个编程模型,又是一个计算框架。也就是说,开发人员必须基于MapReduce编程模型进行编程开发,然后将程序通过MapReduce计算框架分发到Hadoop集群中运行。我们先看一下作为编程模型的MapReduce。
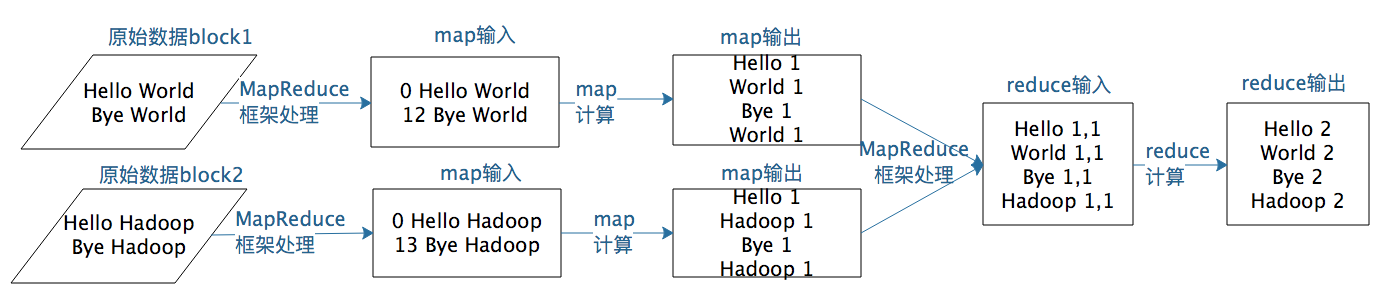
举个WordCount的例子,WordCount主要解决的是文本处理中词频统计的问题,就是统计文本中每一个单词出现的次数。MapReduce版本WordCount程序的核心是一个map函数和一个reduce函数。
map函数的输入主要是一个\u0026lt;Key, Value\u0026gt;对,在这个例子里,Value是要统计的所有文本中的一行数据,Key在一般计算中都不会用到。
map函数的计算过程是,将这行文本中的单词提取出来,针对每个单词输出一个\u0026lt;word, 1\u0026gt;这样的\u0026lt;Key, Value\u0026gt;对。
MapReduce计算框架会将这些\u0026lt;word , 1\u0026gt;收集起来,将相同的word放在一起,形成\u0026lt;word , \u0026lt;1,1,1,1,1,1,1…\u0026gt;\u0026gt;这样的\u0026lt;Key, Value集合\u0026gt;数据,然后将其输入给reduce函数。
这里reduce的输入参数Values就是由很多个1组成的集合,而Key就是具体的单词word。
reduce函数的计算过程是,将这个集合里的1求和,再将单词(word)和这个和(sum)组成一个\u0026lt;Key, Value\u0026gt;,也就是\u0026lt;word, sum\u0026gt;输出。每一个输出就是一个单词和它的词频统计总和。
一个map函数可以针对一部分数据进行运算,这样就可以将一个大数据切分成很多块(这也正是HDFS所做的),MapReduce计算框架为每个数据块分配一个map函数去计算,从而实现大数据的分布式计算。
接下来我们来看作为计算框架,MapReduce是如何运作的。
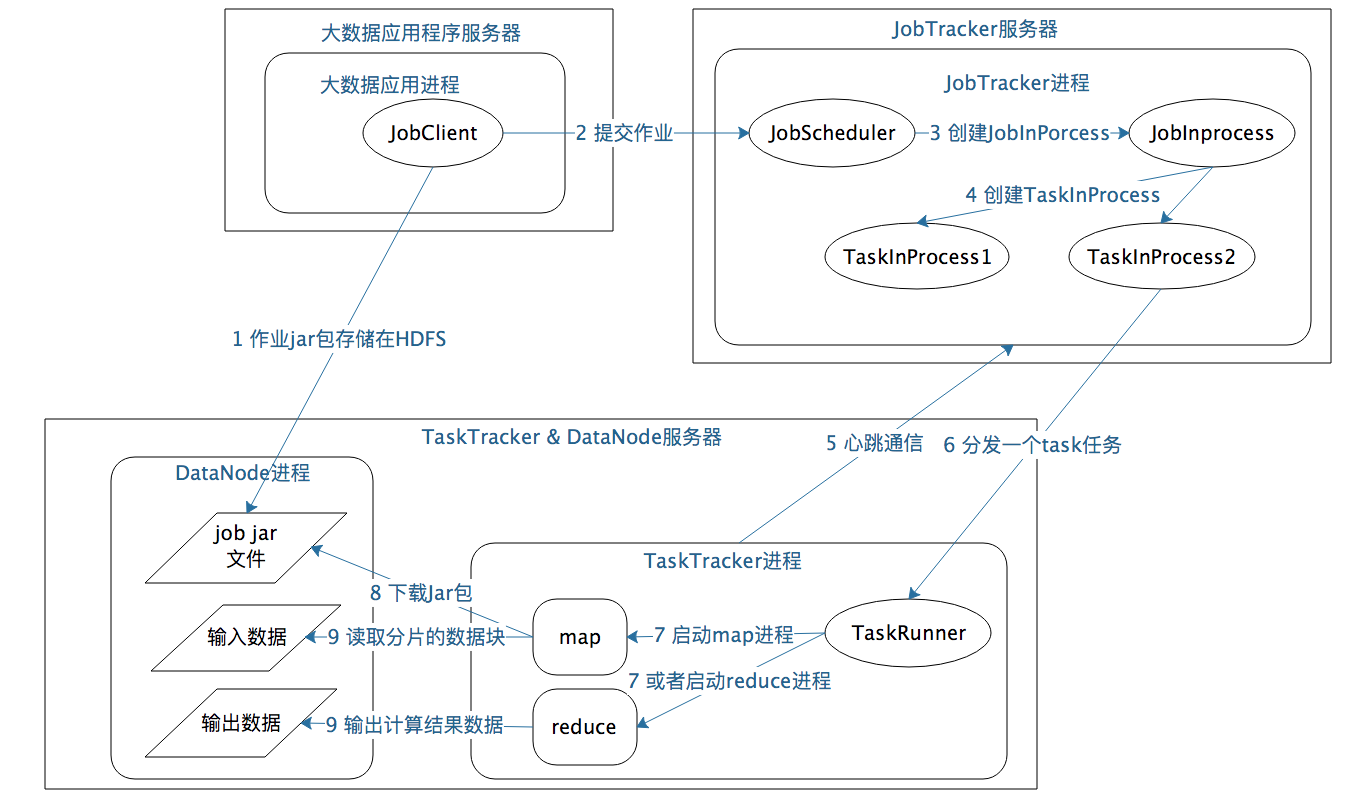
以Hadoop 1为例,MapReduce运行过程涉及三类关键进程。
- 大数据应用进程。这类进程是启动MapReduce程序的主入口,主要是指定Map和Reduce类、输入输出文件路径等,并提交作业给Hadoop集群,也就是下面提到的JobTracker进程。这是由用户启动的MapReduce程序进程,比如WordCount程序。
- JobTracker进程。这类进程根据要处理的输入数据量,命令下面提到的TaskTracker进程启动相应数量的Map和Reduce进程任务,并管理整个作业生命周期的任务调度和监控。这是Hadoop集群的常驻进程,需要注意的是,JobTracker进程在整个Hadoop集群全局唯一。
- TaskTracker进程。这个进程负责启动和管理Map进程以及Reduce进程。因为需要每个数据块都有对应的map函数,TaskTracker进程通常和HDFS的DataNode进程启动在同一个服务器。也就是说,Hadoop集群中绝大多数服务器同时运行DataNode进程和TaskTacker进程。
MapReduce计算真正产生奇迹的地方是数据的合并与连接。
还是回到WordCount例子中,我们想要统计相同单词在所有输入数据中出现的次数,而一个Map只能处理一部分数据,一个热门单词几乎会出现在所有的Map中,这意味着同一个单词必须要合并到一起进行统计才能得到正确的结果。
在map输出与reduce输入之间,MapReduce计算框架处理数据合并与连接操作,这个操作有个专门的词汇叫shuffle。那到底什么是shuffle?shuffle的具体过程又是怎样的呢?请看下图。
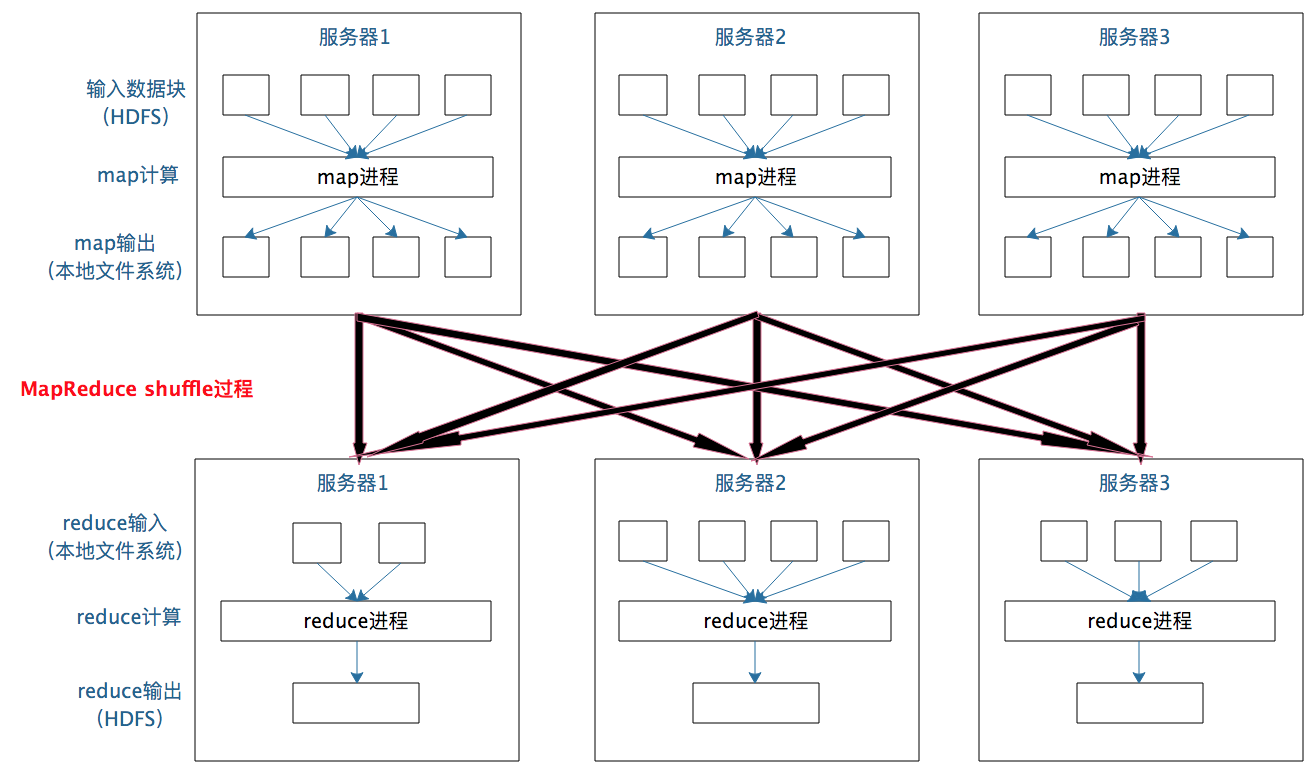
每个Map任务的计算结果都会写入到本地文件系统,等Map任务快要计算完成的时候,MapReduce计算框架会启动shuffle过程,在Map任务进程调用一个Partitioner接口,对Map产生的每个\u0026lt;Key, Value\u0026gt;进行Reduce分区选择,然后通过HTTP通信发送给对应的Reduce进程。这样不管Map位于哪个服务器节点,相同的Key一定会被发送给相同的Reduce进程。Reduce任务进程对收到的\u0026lt;Key, Value\u0026gt;进行排序和合并,相同的Key放在一起,组成一个\u0026lt;Key, Value集合\u0026gt;传递给Reduce执行。
map输出的\u0026lt;Key, Value\u0026gt;shuffle到哪个Reduce进程是这里的关键,它是由Partitioner来实现,MapReduce框架默认的Partitioner用Key的哈希值对Reduce任务数量取模,相同的Key一定会落在相同的Reduce任务ID上。
讲了这么多,对shuffle的理解,你只需要记住这一点:分布式计算需要将不同服务器上的相关数据合并到一起进行下一步计算,这就是shuffle。
BigTable的开源实现:HBase
HBase为可伸缩海量数据储存而设计,实现面向在线业务的实时数据访问延迟。HBase的伸缩性主要依赖其可分裂的HRegion及可伸缩的分布式文件系统HDFS实现。
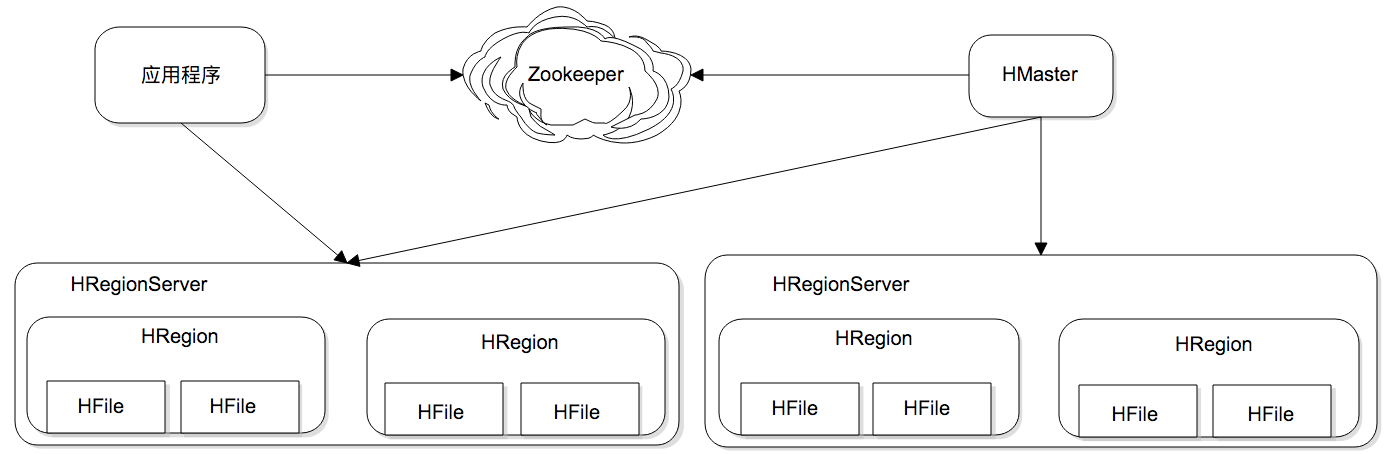
HRegion是HBase负责数据存储的主要进程,应用程序对数据的读写操作都是通过和HRetion通信完成。上面是HBase架构图,我们可以看到在HBase中,数据以HRegion为单位进行管理,也就是说应用程序如果想要访问一个数据,必须先找到HRegion,然后将数据读写操作提交给HRegion,由 HRegion完成存储层面的数据操作。
HRegionServer是物理服务器,每个HRegionServer上可以启动多个HRegion实例。当一个 HRegion中写入的数据太多,达到配置的阈值时,一个HRegion会分裂成两个HRegion,并将HRegion在整个集群中进行迁移,以使HRegionServer的负载均衡。
每个HRegion中存储一段Key值区间[key1, key2)的数据,所有HRegion的信息,包括存储的Key值区间、所在HRegionServer地址、访问端口号等,都记录在HMaster服务器上。为了保证HMaster的高可用,HBase会启动多个HMaster,并通过ZooKeeper选举出一个主服务器。
下面是一张调用时序图,应用程序通过ZooKeeper获得主HMaster的地址,输入Key值获得这个Key所在的HRegionServer地址,然后请求HRegionServer上的HRegion,获得所需要的数据。
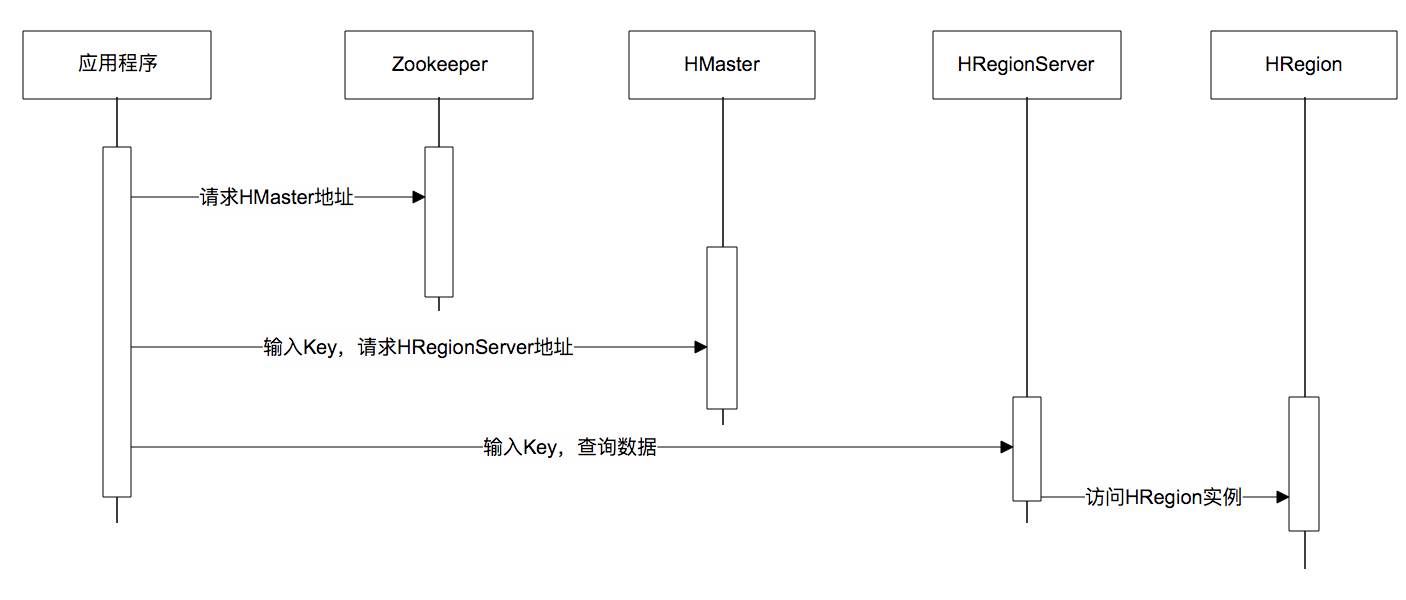
数据写入过程也是一样,需要先得到HRegion才能继续操作。HRegion会把数据存储在若干个HFile格式的文件中,这些文件使用HDFS分布式文件系统存储,在整个集群内分布并高可用。当一个HRegion中数据量太多时,这个HRegion连同HFile会分裂成两个HRegion,并根据集群中服务器负载进行迁移。如果集群中有新加入的服务器,也就是说有了新的HRegionServer,由于其负载较低,也会把HRegion迁移过去并记录到HMaster,从而实现HBase的线性伸缩。
作者简介:
李智慧,专栏作者,同程艺龙交通首席架构师、Apache Spark 源代码贡献者,长期从事大数据、大型网站架构的研发工作,曾担任阿里巴巴技术专家、Intel亚太研发中心架构师、宅米和WiFi万能钥匙CTO,有超过6年的线下咨询、培训经验,著有畅销书《大型网站技术架构:核心原理与案例分析》。转载地址:http://kkoux.baihongyu.com/